Development installation
These are development setup and standards that are followed to by the core development team. If you are a contributor to Read the Docs, it might a be a good idea to follow these guidelines as well.
Requirements
A development setup can be hosted by your laptop, in a VM, on a separate server etc. Any such scenario should work fine, as long as it can satisfy the following:
Is Unix-like system (Linux, BSD, Mac OSX) which supports Docker. Windows systems should have WSL+Docker or Docker Desktop.
Has 10 GB or more of free disk space on the drive where Docker’s cache and volumes are stored. If you want to experiment with customizing Docker containers, you’ll likely need more.
Can spare 2 GB of system memory for running Read the Docs, this typically means that a development laptop should have 8 GB or more of memory in total.
Your system should ideally match the production system which uses the latest official+stable Docker distribution for Ubuntu (the
docker-cepackage). If you are on Windows or Mac, you may also want to try Docker Desktop.
Note
Take into account that this setup is intended for development purposes. We do not recommend to follow this guide to deploy an instance of Read the Docs for production.
Install external dependencies (Docker, Docker Compose, gVisor)
Install Docker by following the official guide.
Install Docker Compose with the official instructions.
Install and set up gVisor following gVisor installation.
Set up your environment
Clone the
readthedocs.orgrepository:git clone --recurse-submodules https://github.com/readthedocs/readthedocs.org/Install or clone additional repositories:
Note
This step is only required for Read the Docs core team members.
Core team should at very least have all required packages installed in their development image. To install these packages you must define a GitHub token before building your image:
export GITHUB_TOKEN="..." export GITHUB_USER="..."
In order to make development changes on any of our private repositories, such as
readthedocs-extorext-theme, you will also need to check these repositories out:git clone --recurse-submodules https://github.com/readthedocs/readthedocs-ext/Install the requirements from
commonsubmodule:pip install -r common/dockerfiles/requirements.txtBuild the Docker image for the servers:
Warning
This command could take a while to finish since it will download several Docker images.
inv docker.buildPull down Docker images for the builders:
inv docker.pullStart all the containers:
inv docker.up --init # --init is only needed the first timeGo to http://devthedocs.org to access your local instance of Read the Docs.
Check that everything works
Visit http://devthedocs.org
Login as
admin/adminand verify that the project list appears.Go to the “Read the Docs” project, under section Build a version, click on the Build version button selecting “latest”, and wait until it finishes (this can take several minutes).
Warning
Read the Docs will compile the Python/Node.js/Rust/Go version on-the-fly each time when building the documentation.
To speed things up, you can pre-compile and cache all these versions by using inv docker.compilebuildtool command.
We strongly recommend to pre-compile these versions if you want to build documentation on your development instance.
Click on the “View docs” button to browse the documentation, and verify that it shows the Read the Docs documentation page.
Working with Docker Compose
We wrote a wrapper with invoke around docker-compose to have some shortcuts and
save some work while typing docker compose commands. This section explains these invoke commands:
inv docker.buildBuilds the generic Docker image used by our servers (web, celery, build and proxito).
inv docker.upStarts all the containers needed to run Read the Docs completely.
--no-searchcan be passed to disable search--initis used the first time this command is ran to run initial migrations, create an admin user, etc--no-reloadmakes all celery processes and django runserver to use no reload and do not watch for files changes--no-django-debugruns all containers withDEBUG=False--http-domainconfigures an external domain for the environment (useful for Ngrok or other http proxy). Note that https proxies aren’t supported. There will also be issues with “suspicious domain” failures on Proxito.--ext-themeto use the new dashboard templates--webpackto start the Webpack dev server for the new dashboard templates
inv docker.shellOpens a shell in a container (web by default).
--no-runningspins up a new container and open a shell--containerspecifies in which container the shell is open
inv docker.manage {command}Executes a Django management command in a container.
Tip
Useful when modifying models to run
makemigrations.inv docker.downStops and removes all containers running.
--volumeswill remove the volumes as well (database data will be lost)
inv docker.restart {containers}Restarts the containers specified (automatically restarts NGINX when needed).
inv docker.attach {container}Grab STDIN/STDOUT control of a running container.
Tip
Useful to debug with
pdb. Once the program has stopped in your pdb line, you can runinv docker.attach weband jump into a pdb session (it also works with ipdb and pdb++)Tip
You can hit CTRL-p CTRL-p to detach it without stopping the running process.
inv docker.testRuns all the test suites inside the container.
--argumentswill pass arguments to Tox command (e.g.--arguments "-e py310 -- -k test_api")
inv docker.pullDownloads and tags all the Docker images required for builders.
--only-requiredpulls only the imageubuntu-20.04.
inv docker.buildassetsBuild all the assets and “deploy” them to the storage.
inv docker.compilebuildtoolPre-compile and cache tools that can be specified in
build.toolsto speed up builds. It requiresinv docker.uprunning in another terminal to be able to upload the pre-compiled version to the cache.
Adding a new Python dependency
The Docker image for the servers is built with the requirements defined in the current checked out branch.
In case you need to add a new Python dependency while developing,
you can use the common/dockerfiles/entrypoints/common.sh script as shortcut.
This script is run at startup on all the servers (web, celery, builder, proxito) which
allows you to test your dependency without re-building the whole image.
To do this, add the pip command required for your dependency in common.sh file:
# common.sh
pip install my-dependency==1.2.3
Once the PR that adds this dependency was merged, you can rebuild the image so the dependency is added to the Docker image itself and it’s not needed to be installed each time the container spins up.
Debugging Celery
In order to step into the worker process, you can’t use pdb or ipdb, but
you can use celery.contrib.rdb:
from celery.contrib import rdb
rdb.set_trace()
When the breakpoint is hit, the Celery worker will pause on the breakpoint and
will alert you on STDOUT of a port to connect to. You can open a shell into the container
with inv docker.shell celery (or build) and then use telnet or netcat
to connect to the debug process port:
nc 127.0.0.1 6900
The rdb debugger is similar to pdb, there is no ipdb for remote
debugging currently.
Configuring connected accounts
These are optional steps to setup the connected accounts (GitHub, Bitbucket, and GitLab) in your development environment. This will allow you to login to your local development instance using your GitHub, Bitbucket, or GitLab credentials and this makes the process of importing repositories easier.
However, because these services will not be able to connect back to your local development instance, incoming webhooks will not function correctly. For some services, the webhooks will fail to be added when the repository is imported. For others, the webhook will simply fail to connect when there are new commits to the repository.
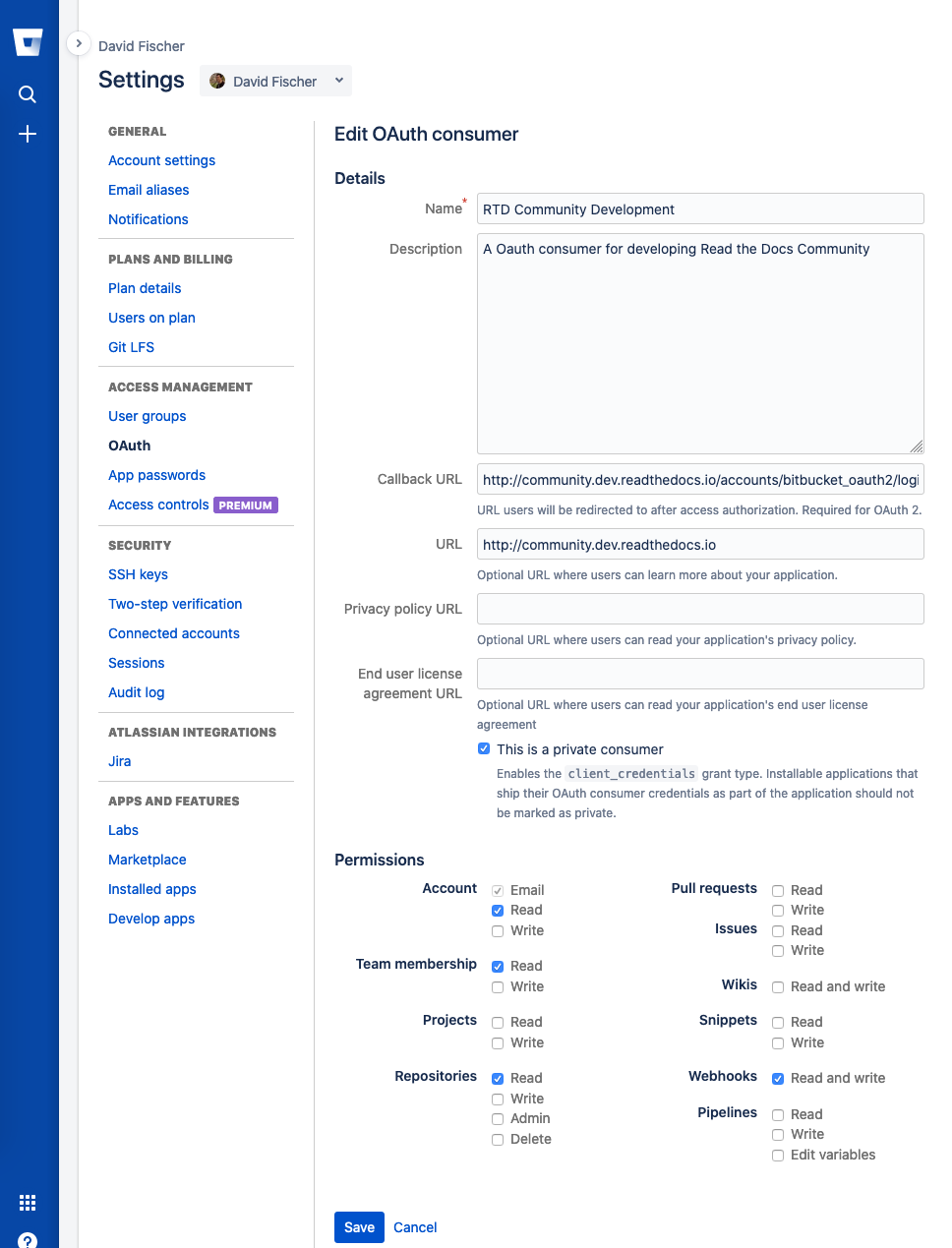
Configuring an OAuth consumer for local development on Bitbucket
Configure the applications on GitHub, Bitbucket, and GitLab. For each of these, the callback URI is
http://devthedocs.org/accounts/<provider>/login/callback/where<provider>is one ofgithub,gitlab, orbitbucket_oauth2. When setup, you will be given a “Client ID” (also called an “Application ID” or just “Key”) and a “Secret”.Take the “Client ID” and “Secret” for each service and enter it in your local Django admin at:
http://devthedocs.org/admin/socialaccount/socialapp/. Make sure to apply it to the “Site”.
Troubleshooting
Warning
The environment is developed and mainly tested on Docker Compose v1.x.
If you are running Docker Compose 2.x, please make sure you have COMPOSE_COMPATIBILITY=true set.
This is automatically loaded via the .env file.
If you want to ensure that the file is loaded, run:
source .env
Builds fail with a generic error
There are projects that do not use the default Docker image downloaded when setting up the development environment. These extra images are not downloaded by default because they are big and they are not required in all cases. However, if you are seeing the following error
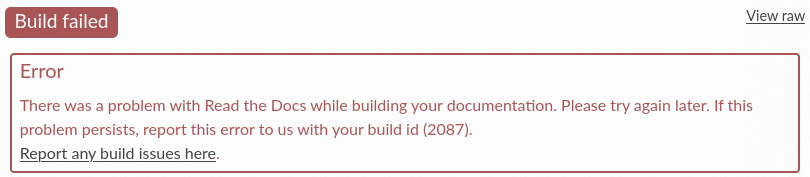
Build failing with a generic error
and in the console where the logs are shown you see something like BuildAppError: No such image: readthedocs/build:ubuntu-22.04,
that means the application wasn’t able to find the Docker image required to build that project and it failed.
In this case, you can run a command to download all the optional Docker images:
inv docker.pull
However, if you prefer to download only the specific image required for that project and save some space on disk, you have to follow these steps:
find the latest tag for the image shown in the logs (in this example is
readthedocs/build:ubuntu-22.04, which the current latest tag on that page isubuntu-22.04-2022.03.15)run the Docker command to pull it:
docker pull readthedocs/build:ubuntu-22.04-2022.03.15tag the downloaded Docker image for the app to findit:
docker tag readthedocs/build:ubuntu-22.04-2022.03.15 readthedocs/build:ubuntu-22.04
Once this is done, you should be able to trigger a new build on that project and it should succeed.
Core team standards
Core team members expect to have a development environment that closely approximates our production environment, in order to spot bugs and logical inconsistencies before they make their way to production.
This solution gives us many features that allows us to have an environment closer to production:
- Celery runs as a separate process
Avoids masking bugs that could be introduced by Celery tasks in a race conditions.
- Celery runs multiple processes
We run celery with multiple worker processes to discover race conditions between tasks.
- Docker for builds
Docker is used for a build backend instead of the local host build backend. There are a number of differences between the two execution methods in how processes are executed, what is installed, and what can potentially leak through and mask bugs – for example, local SSH agent allowing code check not normally possible.
- Serve documentation under a subdomain
There are a number of resolution bugs and cross-domain behavior that can only be caught by using a
PUBLIC_DOMAINsetting different from thePRODUCTION_DOMAINsetting.- PostgreSQL as a database
It is recommended that Postgres be used as the default database whenever possible, as SQLite has issues with our Django version and we use Postgres in production. Differences between Postgres and SQLite should be masked for the most part however, as Django does abstract database procedures, and we don’t do any Postgres-specific operations yet.
- Celery is isolated from database
Celery workers on our build servers do not have database access and need to be written to use API access instead.
- Use NGINX as web server
All the site is served via NGINX with the ability to change some configuration locally.
- MinIO as Django storage backend
All static and media files are served using Minio –an emulator of S3, which is the one used in production.
- Serve documentation via El Proxito
El Proxito is a small application put in front of the documentation to serve files from the Django Storage Backend.
- Use Cloudflare Wrangler
Documentation pages are proxied by NGINX to Wrangler, who executes a JavaScript worker to fetch the response from El Proxito and injects HTML tags (for addons) based on HTTP headers.
- Search enabled by default
Elasticsearch is properly configured and enabled by default. All the documentation indexes are updated after a build is finished.